Airflow healthcheck
I’ve been running Airflow for some years and in my experience, the scheduler sometimes gets stuck. I haven’t figured out why this happens, and to my knowledge, no one else has. This doesn’t stop me from using Airflow but the issue needs to be addressed or it will bite you at some point, because your pipelines will stall.
I read the article Airflow on AKS this week and it is a good overview of how to deploy Airflow on AKS. However, the final bit describes how the scheduler gets terminated every 5 minutes by chaoskube, which is a bit drastic for my taste. I’ve implemented a solution before that reliably reboots the scheduler whenever it fails, not on a regular period.
Goal
We want to monitor Airflow end-to-end. If you just check the Airflow PID, all you know is that the process is still running. But it could be stuck. So we will monitor two things:
- Airflow scheduler is still scheduling tasks
- Those tasks actually get executed and finish successfully
If the task does not finish in time, the scheduler is restarted.
Solution description
The following diagram describes the solution. A DAG is scheduled every 5 minutes. The DAG contains a PythonOperator that stores a heartbeat in the Airflow database. A healthcheck compares the timestamp in the database with the current timestamp, and if the timestamp has not been updated, the scheduler is assumed to be stuck and will be restarted.
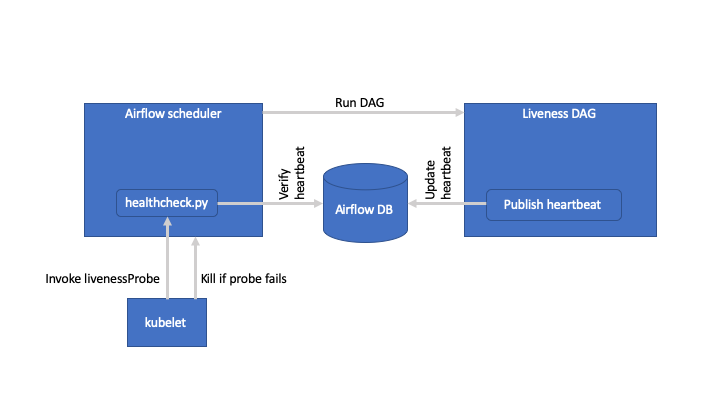
Note that killing the scheduler may not actually solve the problem if the tasks do not finish for other reasons; such as a lack of compute resources in your namespace. I think the real issue here is that there is no out-of-the-box healthcheck for the scheduler (see Airflow-1084). Recently, a healthcheck was added but that is exposed on the webserver, not the scheduler. But the solution implemented here goes a long way to solving the ‘scheduler is stuck’ syndrome. Still, I’d monitor some metrics (like # of tasks scheduled / completed) and put alerts on that, too.
Implementation
The code below is based on two assumptions:
- You run Airflow on Kubernetes
- You use Postgres
If this is the case, you can copy this solution literally. But if your Airflow deployment looks different (e.g. a different database) the concept is still valid and you can easily adapt the solution for your needs.
heartbeat_dag.py
from airflow.models import DAG
from airflow.models import settings
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
import logging
"""
Updates timestamp in the airflow db, healthcheck table
"""
session = settings.Session()
default_args = {
'owner': 'ops',
'depends_on_past': False,
'email': 'roland@de-boo.nl',
'email_on_failure': True,
'email_on_retry': False,
'execution_timeout': timedelta(minutes=1),
'retries': 0,
'retry_delay': timedelta(minutes=1)
}
START_DATE = datetime(2019, 1, 1, 0, 30, 0)
dag = DAG('heartbeat_dag',
default_args=default_args,
schedule_interval='*/5 * * * *',
max_active_runs=1,
start_date=START_DATE,
catchup=False)
def update_timestamp_function(**context):
logging.info("Updating timestamp in healthcheck table")
session.execute("insert into healthcheck(worker_heartbeat_ts) values (current_timestamp)")
logging.info("Finished Updating timestamp in healthcheck table")
update_task = PythonOperator(
task_id='update_timestamp',
python_callable=update_timestamp_function,
provide_context=True,
dag=dag
)
healthcheck.py
In Kubernetes you have options to define a livenessProbe. It can be a HTTP probe or a command. We will use a command. The logic is placed in this file healthcheck.py which we will periodically execute:
from airflow.models import settings
from datetime import datetime, timezone
# 10 minutes, the maximum number of seconds that we wait for the liveness task to update value in the database.
# After this number is reached, kubernetes will kill the scheduler pod.
max_execution_delay = 600
session = settings.Session()
result = session.execute("select max(worker_heartbeat_ts) from healthcheck").fetchall()
if (len(result)) == 0:
raise Exception('No execution_ts found!')
else:
most_recent_ts = dict(result[0])['max']
delta = datetime.now(timezone.utc) - most_recent_ts
print(f'Last execution was {delta.seconds} seconds ago')
if delta.seconds > max_execution_delay: # 10 minutes
raise Exception(f'Last execution was on {most_recent_ts}. This is {delta.seconds} second ago, maximum permitted: {max_execution_delay}!')
Deployment
You will need to deploy these 2 files (the healthcheck and the heartbeat DAG) on on your containers. The easiest way is to just bake them into the docker image.
Adding the healthcheck to Kubernetes
We will use a command livenessProbe to execute the healthcheck.
In the Kubernetes manifest that describes the deployment of the scheduler, define the livenessProbe. This is in the container spec (same level as imagePullPolicy).
livenessProbe:
exec:
command:
- python
- /opt/airflow/healthcheck.py
failureThreshold: 1
initialDelaySeconds: 600
periodSeconds: 600
successThreshold: 1
timeoutSeconds: 20
You can play with the numbers, but note that the 600 seconds correspond to max_execution_delay in healthcheck.py.
Creating the database table
Finally, create the necessary table in PostgreSQL:
CREATE TABLE public.healthcheck (
worker_heartbeat_ts timestamptz NULL
);
CREATE INDEX healthcheck_index ON public.healthcheck USING btree (worker_heartbeat_ts);
Verifying that it works
After this has been deployed for a while, you can run kubectl describe pod <airflow scheduler> and you might see something like this:
Warning Unhealthy 34m kubelet, aks-agentpool-56930946-2 Liveness probe failed: [2019-07-01 08:08:44,206] {settings.py:182} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=1812
Last execution was 787 seconds ago
Traceback (most recent call last):
File "/opt/airflow/healthcheck.py", line 20, in <module>
raise Exception(f'Last execution was on {most_recent_ts}. This is {delta.seconds} second ago, maximum permitted: {max_execution_delay}!')
Exception: Last execution was on 2019-07-01 07:55:39.457244+00:00. This is 787 second ago, maximum permitted: 600!
Normal Killing 33m (x225 over 3d19h) kubelet, aks-agentpool-56930946-2 Killing container with id docker://airflow-scheduler:Container failed liveness probe.. Container will be killed and recreated.
This means that Kubernetes has restarted the scheduler.
And that is it! Since we have deployed this mechanism, Airflow has been restarted every now and then, but we haven’t seen big issues. And while I partly feel that we should maybe dive deeper into why the scheduler gets stuck, it is also a dirty secret of our industry that most systems benefit from periodic rebooting :)